TPA Claims Processing: Where Indian Hospitals Lose Money
Alok Mani · · 11 min read · Healthcare
Share: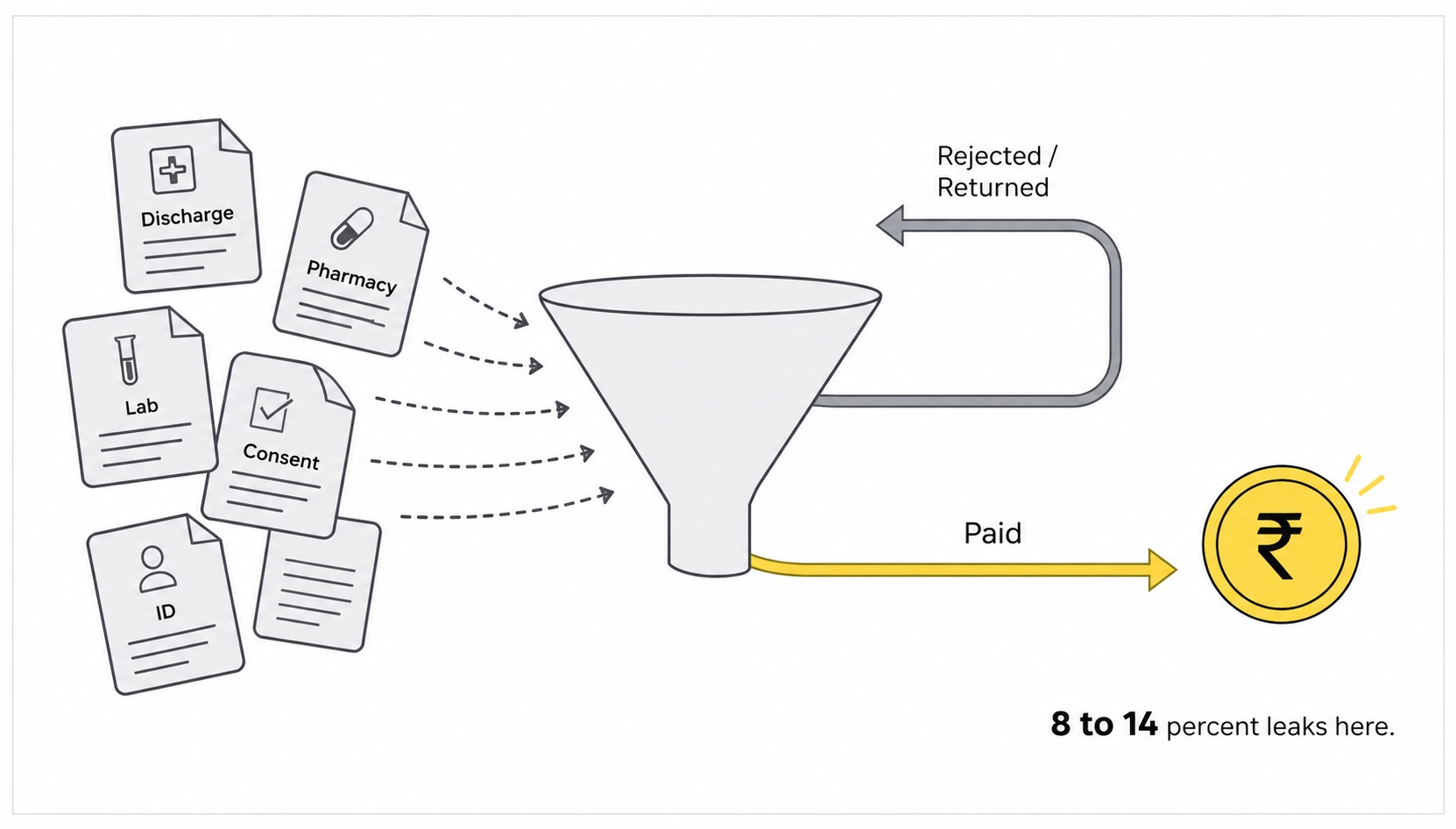
Indian hospitals do not lose money in operation theatres.
They lose it in the room next to the billing counter. The one with three people in green and grey uniforms, surrounded by stacks of paper, frantically photocopying discharge summaries and trying to make the names on the Aadhaar match the names on the policy document before the TPA portal closes at 6 PM.
This is where 8 to 14 percent of every TPA claim value quietly disappears. Not in surgery costs. Not in pharmacy waste. In the document pipeline.
The CFO of a 150 bed hospital in Pune put it to me bluntly last quarter. "I do not have a clinical problem. I have a documentation problem. My doctors are world class. My claim rejection rate is 22 percent. The gap is paperwork."
That gap costs Indian hospitals more than any single line item on their P&L. And almost nobody is talking about it.
The TPA claims document chain nobody designed
Walk through what actually happens when a cashless patient gets discharged from an Indian hospital.
- The doctor writes a discharge summary, often handwritten or partially handwritten with stamps and signatures.
- The pharmacy generates an itemised bill, sometimes from the HIS, sometimes from a separate billing software.
- Investigation reports come from the radiology and pathology departments, each in their own format.
- Consent forms and admission documents are pulled from physical files.
- The patient's policy card, Aadhaar, and PAN are photocopied.
- A claims executive sits down and manually assembles the pack, types the values into the TPA portal, uploads scanned documents, and hits submit.
The chain has 15 to 25 documents per claim. Each document was created by a different system or human, on a different format, at a different time. Nothing is structured. Nothing cross-validates. The claims executive is the integration layer.
This is why claims fail. Not because the medicine was wrong. Because the patient's name on the discharge summary has a middle initial that is missing on the Aadhaar.
The hidden cost map most hospitals never draw
Hospitals track gross billing and net realisation. They rarely track the leakage in between. Here is what the actual breakdown looks like for an average 150 bed hospital with 60 percent TPA business.
Notice that four of the five leakage buckets trace back to documents. Only the finance cost is downstream of operations, and even that is caused by the delays the documents create.
This is the part hospitals systematically underinvest in. They will spend 30 lakh on a new ultrasound machine that maybe runs 8 hours a day. They will not spend 5 lakh on fixing the document pipeline that runs 24 hours a day and bleeds 6 crore a year.
Hospitals will spend 30 lakh on equipment that runs 8 hours a day. They will not spend 5 lakh on the document pipeline that bleeds 6 crore a year.
Why OCR fails on hospital documents specifically
Most hospital IT teams have tried OCR at some point. Usually after a vendor pitch promising "AI-powered claims automation." The pilot looks great on a clean discharge summary. Production tells a different story.
Hospital documents are harder than almost any other document category. Here is why.
- Handwritten content everywhere. Doctor notes, progress charts, OT records, prescription pads. OCR built for printed text falls apart on doctor handwriting, which is its own special challenge.
- Stamps and signatures over text. Hospital documents have official stamps, doctor signatures, and verification marks layered on top of critical fields like dates, diagnoses, and amounts.
- Multi-format pharmacy bills. A single hospital may have 3 different pharmacy billing formats from different POS systems, plus handwritten indents from the ICU.
- Lab reports with embedded images. Pathology and radiology reports mix tables, graphs, scan thumbnails, and free text.
- Multilingual content. Patient names in Hindi, Marathi, Tamil. Doctor names with regional initials. Insurance company names abbreviated differently across documents.
- Cross-document validation. The patient name on the discharge summary must match the policy. The diagnosis must match the ICD code. The pharmacy items must reconcile to the prescription. OCR has no way to check these relationships.
This is why OCR-based claims tools deliver 70 to 75 percent accuracy on real hospital documents. Sounds high until you do the math. At 25 percent error rate across 20 fields per claim, every single claim needs human review. Your automation has become a slow data entry system with extra steps.
What AI-Powered IDP changes in the hospital claims pipeline
AI-Powered IDP, or Intelligent Document Processing, is not better OCR. It is a different category of system.
OCR reads characters. IDP reads documents. The shift matters because claim preparation is not a text problem. It is a cross-document understanding problem.
When an experienced claims executive prepares a TPA submission, they do not just type fields. They read the discharge summary, check that the diagnosis matches the surgery code, verify the pharmacy bill items are consistent with the prescription, confirm the doctor's signature appears on the consent form, and ensure the patient name format is identical across all documents.
AI-Powered IDP does the same checks, automatically, in seconds.
The structural difference matters. With AI-Powered IDP, your team stops being typists and cross-checkers. They become exception handlers. The 88 to 92 percent of claims that pass automated validation go to the TPA portal in clean shape on day one. The remaining 8 to 12 percent get flagged with the specific issue and the specific document, so the human review is fast and targeted.
What hospitals see in production
The numbers from hospitals running AI-Powered IDP in their claims pipeline are not theoretical. They are showing up in monthly P&L reviews.
- First-pass TPA rejection rate drops from 22-28 percent to 8-12 percent
- Average claim submission time drops from 36 hours to 4 hours after discharge
- Days sales outstanding on TPA receivables compresses by 15 to 25 days
- Claims executive team can handle 3x the volume per person
- Overall TPA realisation rate improves by 6 to 9 percentage points
For a hospital doing 50 crore TPA revenue, a 6 percentage point realisation improvement is 3 crore added to the bottom line. The investment in AI-Powered IDP is a fraction of that.
This is not a software ROI story. It is a working capital and bottom line story.
What we have learned building DocXtract for hospital documents
At RPATech, we have spent the last two years training DocXtract specifically on Indian healthcare documents. The lessons have been humbling.
Our first version applied the same logic we used for invoice extraction. It failed on discharge summaries. Hospital documents have semantic relationships that pharmaceutical invoices do not. The diagnosis on page 1 must validate against the ICD code on page 3. The medication list must reconcile with both the discharge note and the pharmacy bill. The dates must form a coherent timeline of admission, surgery, and discharge.
None of this is rule-based. It needs models that understand what a hospital document is and what each section means in clinical context.
We rebuilt the platform around that understanding. Today DocXtract handles discharge summaries, lab reports, pharmacy bills, consent forms, ID documents, and policy papers in one API call per claim. It cross-validates fields, flags inconsistencies, and outputs a structured JSON that flows directly into HIS, TPA portals, or claims management systems.
If you want the longer story on what we got wrong and how we fixed it, the DocXtract build story is here. The lessons translate directly from invoice extraction to medical document extraction because the underlying problem is the same. Real-world documents are messier than any vendor demo, and only AI trained on that mess holds up at scale.
What hospital CFOs and IT heads should do next
If you are running finance or IT at an Indian hospital with significant TPA business, here is the practical sequence.
- Measure your first-pass rejection rate honestly. Not the gross rejection rate. Specifically the percentage of claims rejected on first submission for documentation reasons, separately from clinical disputes. Most hospitals do not track this and underestimate it by 5 to 10 percentage points.
- Audit your claims desk workload. How many people are doing nothing but assembly and resubmission? How much salary cost is that per crore of TPA revenue? In most hospitals this number is hidden in operations overhead.
- Calculate the working capital impact. What is your average days sales outstanding on TPA receivables? If it is above 60 days, the document pipeline is choking your cash flow.
- Run a proof of concept on real claims. Take 500 historical claims, including some that were rejected. Run them through an AI-Powered IDP platform. Compare the extraction accuracy, cross-validation flags, and the rejections it would have caught.
- Look at integration cost realistically. API-first platforms plug into existing HIS and claims software in weeks. You do not need to replace your billing or claims workflow. You replace only the document extraction and validation layer.
The hospitals that fix the document pipeline in 2026 will operate with leaner claims teams, faster cash cycles, and higher realisation rates. The ones that keep treating the problem as a paperwork issue will keep watching 8 to 14 percent of their TPA revenue quietly disappear.
The medicine is not the leak. The paperwork is. And the paperwork is finally fixable.
FAQ
Why do TPAs reject hospital claims?
Most TPA rejections are not clinical disputes. They are documentation issues. Mismatched names between the discharge summary and the ID proof, illegible doctor notes, missing investigation reports, pharmacy bills with the wrong date format, and ICD codes that do not match the diagnosis. These document-level errors account for 60 to 70 percent of first-pass TPA rejections in India.
How much do hospitals lose to TPA claim rejections?
A typical mid-sized Indian hospital with 100 to 200 beds loses 8 to 14 percent of claim value to outright rejections, deductions, and resubmission cycles. For a hospital doing 50 crore annual TPA revenue, that is 4 to 7 crore lost per year, plus the cost of staff handling resubmissions and the cash flow hit from 60 to 90 day collection cycles.
Can AI fix TPA claim processing?
AI cannot fix clinical disputes, but it can fix the document pipeline that feeds the claim. AI-Powered IDP extracts structured data from discharge summaries, investigation reports, pharmacy bills, and consent forms, validates that fields match across documents, and flags inconsistencies before the claim is submitted. This reduces first-pass rejections by 50 to 70 percent in production deployments.
What documents does AI-Powered IDP handle for hospital claims?
Discharge summaries, investigation and lab reports, pharmacy bills and indents, consent forms, doctor progress notes, OT notes, ICU charts, imaging reports, anaesthesia records, ID proofs, and policy documents. The key is that a single AI platform handles all of these without separate templates per document type or per hospital format.
How does AI-Powered IDP integrate with hospital information systems?
API-first IDP platforms like DocXtract integrate with HIS, EMR, and TPA submission portals through standard JSON endpoints. The integration replaces only the document extraction layer. Your billing software, claim submission workflow, and TPA portals remain unchanged. Typical integration takes a few weeks, not months.